Эконометрика: выбор модели для панельных данных
Панельные данные позволяют лучше учесть неоднородность данных в выборке. Минусом является большее число параметров и снижение эффективности из-за этого.
При использовании панельных данных появляется возможность делать не только модель наименьших квадратов, но также модели с фиксированными или случайными эффектами. Обсудим, как лучше выбрать между тремя вариантами моделей для панельных данных:
- Модель, построенная на множестве панельных данных методом наименьших квадратов (OLS)
- Модель со случайными эффектами (RE)
- Модель с фиксированными эффектами (FE)
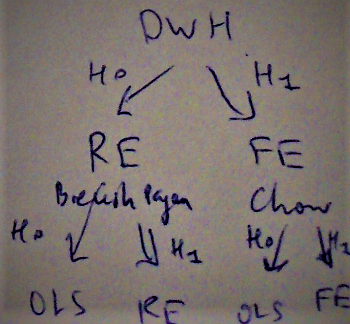
Шаг 1. Выбрать между RE и FE с помощью теста Дарбин-Ву-Хаусмана (Durbin-Wu-Hausman test). Нулевая гипотеза (H0): "методы RE и FE дают модели статистически неразличимого качества". Другими словами, методы RE и FE дают прогноз схожего качества. Какой прогноз выбирается в таком случае? Выбираем RE, поскольку в модели RE при прочих равных меньше параметров, чем в модели FE. Это происходит за счет исключения бинарных регрессоров, ответственных за фиксированные эффекты в модели FE. Принцип парсимонии в действии. Итак, модель RE предпочтительнее, когда не отвергается H0. Если H0 отвергается, берем FE.
Шаг 2. Сравниваем модель, выбранную на шаге 1, с OLS.
Шаг 2.1. Если на шаге 1 выбрана модель RE, делаем тест Бройша-Пагана (Breusch-Pagan test). H0: "OLS предпочтительнее по сравнению с RE". H1: "RE предпочтительнее по сравнению с OLS".
Шаг 2.2. Если на шаге 1 выбрана модель FE, делаем тест Чоу (Chow test). H0: "OLS предпочтительнее по сравнению с FE". H1: "FE предпочтительнее по сравнению с OLS".
Основываясь на собственном опыте оценки панельных данных, обычно наилучшей оказывалась модель со случайными эффектами.
Ниже схематично представлен описанный алгоритм:
11.05.2019